
Immaginiamo il seguente scenario: Bob ha sul suo PC otto file che occupano molto spazio, quindi decide di caricare
tutti i file su un servizio in Cloud e di eliminarli dal suo PC. Dopo tanto tempo, Bob scarica sul suo PC gli otto file
che aveva caricato sul Cloud. Ora Bob vorrebbe controllare l'integrità dei suoi file, cioè vorrebbe sapere se i
suoi file sono stati modificati mentre erano sul Cloud oppure no.
In questo post presentiamo una
tecnica basata sulle funzioni hash e sulle strutture dati ad albero che risolve questo problema.
Cos'è una funzione hash
Una funziona hash è una primitiva crittografica che permette di trasformare
una stringa in input di qualsiasi lunghezza in una stringa più corta (di solito di lunghezza fissa), chiamata digest. Il digest può essere visto come l'impronta digitale della stringa di input.
Ad esempio, avendo a disposizione una funziona hash, è possibile dargli in input un intero file per ottenere un digest con una lunghezza pari a 256 bit.
Queste funzioni hash vengono progettate in modo da soddisfare due proprietà:
- Devono essere irreversibili: non deve essere possibile risalire alla stringa di input partendo dal digest. Quindi, se un utente malevolo ottiene un digest, non è in grado di calcolare il file originale;
- Non devono avere collisioni: non devono esistere due input diversi che producano lo stesso digest. Quindi, un utente malevolo non è in grado di sostituire il file originale con un altro file.
Cos'è un albero
Un albero è una struttura dati composta da archi e nodi, con le seguenti caratteristiche:
- Una radice: un nodo che non ha archi entranti, ma solo uscenti.
- Le foglie: nodi che hanno archi entranti, ma non uscenti
- Ogni nodo può avere al massimo un arco entrante.
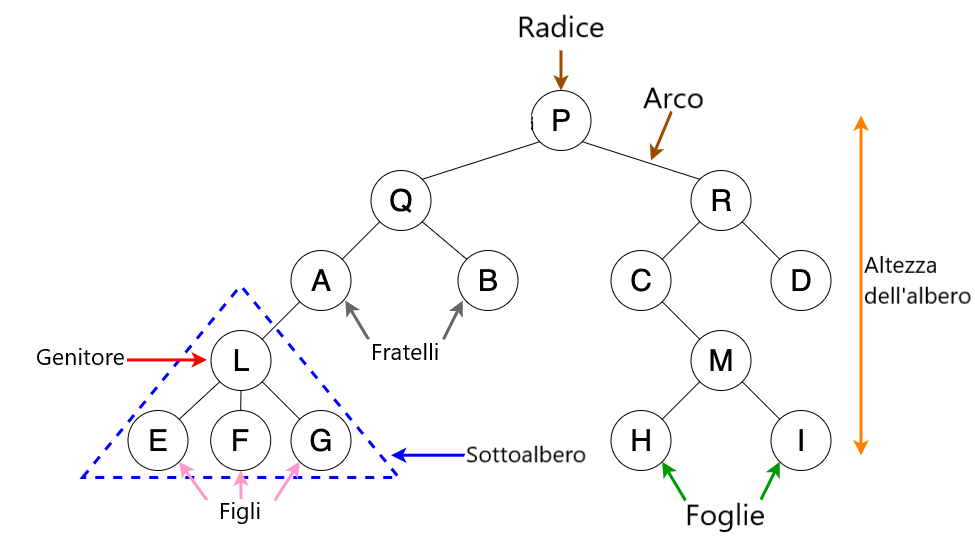
Figura 1. Ogni nodo (tranne la radice) ha un solo arco entrante e può avere uno o più archi uscenti. Un nodo con archi uscenti è chiamato "padre", mentre i nodi con archi entranti sono detti "figli". I nodi privi di figli sono chiamati "foglie", mentre due nodi figli dello stesso padre sono chiamati "fratelli". In un albero si possono individuare più sottoalberi. L'altezza dell'albero è definita come il cammino più lungo dalla radice a una foglia.
Il Merkle Tree
Questa struttura ad albero permette di verificare l'integrità di un insieme di file, conservando sul proprio dispositivo soltanto un unico digest.
Nello specifico, il Merkle Tree è un albero in cui ogni nodo ha esattamente due figli, tranne ovviamente le foglie che non ne hanno.
In ogni nodo viene salvato un digest: in ogni foglia è presente il digest di un singolo file (quindi si hanno tante foglie quanti sono i file), nei nodi
padre si ha il digest della stringa costruita concatenando i due digest dei nodi figli. Questo processo avviene fino alla radice, quindi fino
ad ottenere un unico digest.
Riprendiamo lo scenario in cui Bob vuole assicurarsi dell'integrità dei suoi otto file:
NOTA: di seguito indicheremo i
file utilizzando la lettera "x", quindi il file uno verrà rappresentato usando x con 1, il file due sarà x con 2 e così via.
-
Per prima cosa, si calcola un digest per ogni file utilizzando le funzioni hash. Questi digest formano le foglie del Merkle Tree.
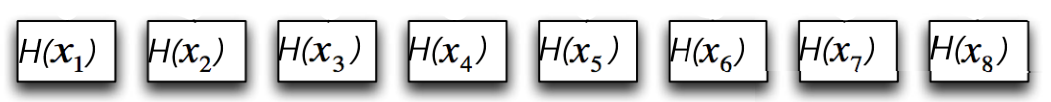
Figura 2. Foglie del Merkle Tree
-
Per ogni coppia di foglie, si calcola il digest della stringa ottenuta dalla concatenazione dei digest presenti nelle due foglie.
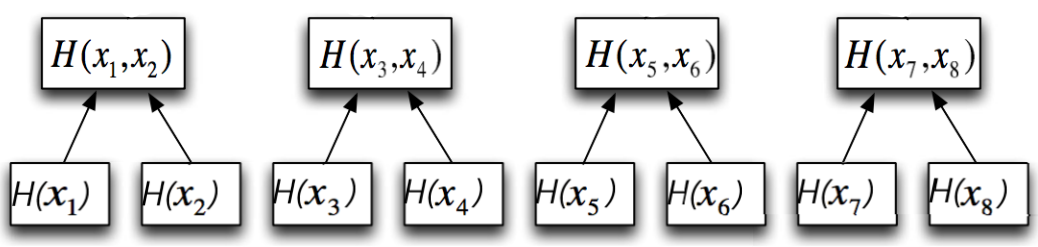
Si aggiungono nodi a partire dalle foglie
-
Il processo viene iterato utilizzando il nuovo livello di nodi fino a completare l'albero e creare la sua radice finale.
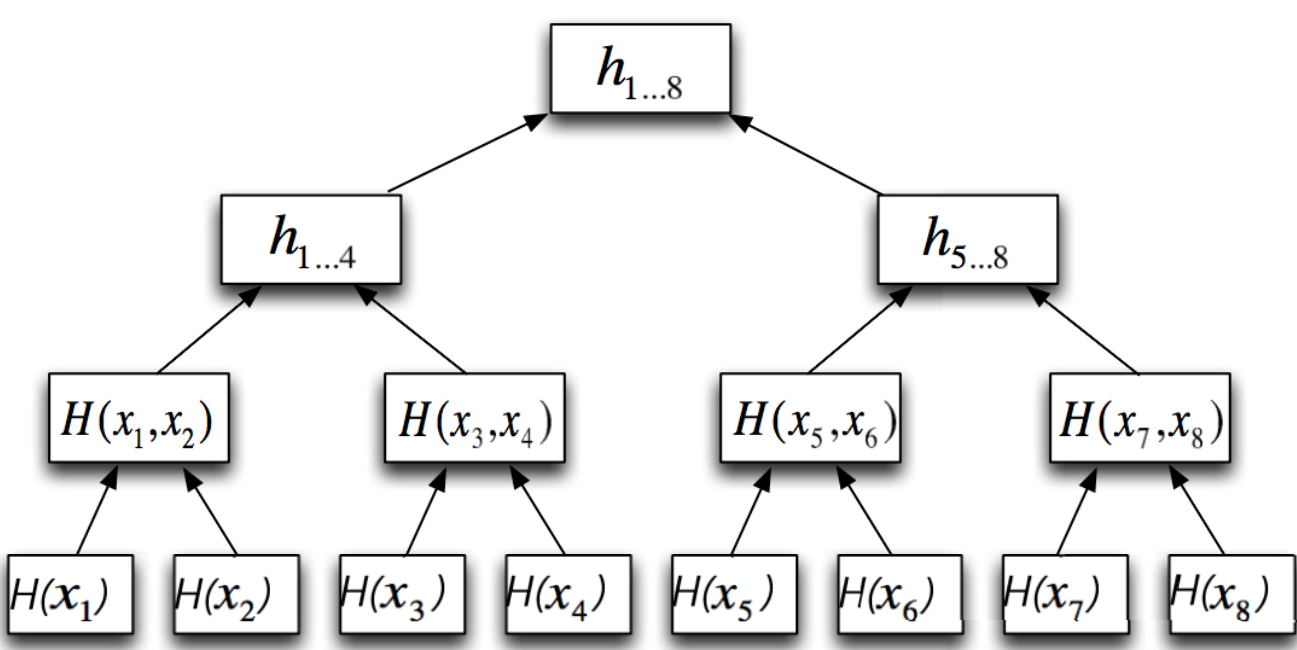
Figura 3. Merkle Tree completo
Una volta completato il Merkle Tree, Bob può caricare tutti i suoi file e il Merkle Tree in Cloud, eliminare i file locali e conservare esclusivamente il digest contenuto nella radice del Merkle Tree. Quando Bob scaricherà dal Cloud, ad esempio, il file numero tre, ricerverà il file tre con tutti i digest dei nodi adiacenti al percorso da x con 3 alla radice. Quindi, il digest di x con 4, il digest di x con 1 concatenato con x con 2, il digest ottenuto concatenando i digest da x con 5 a x con 8.
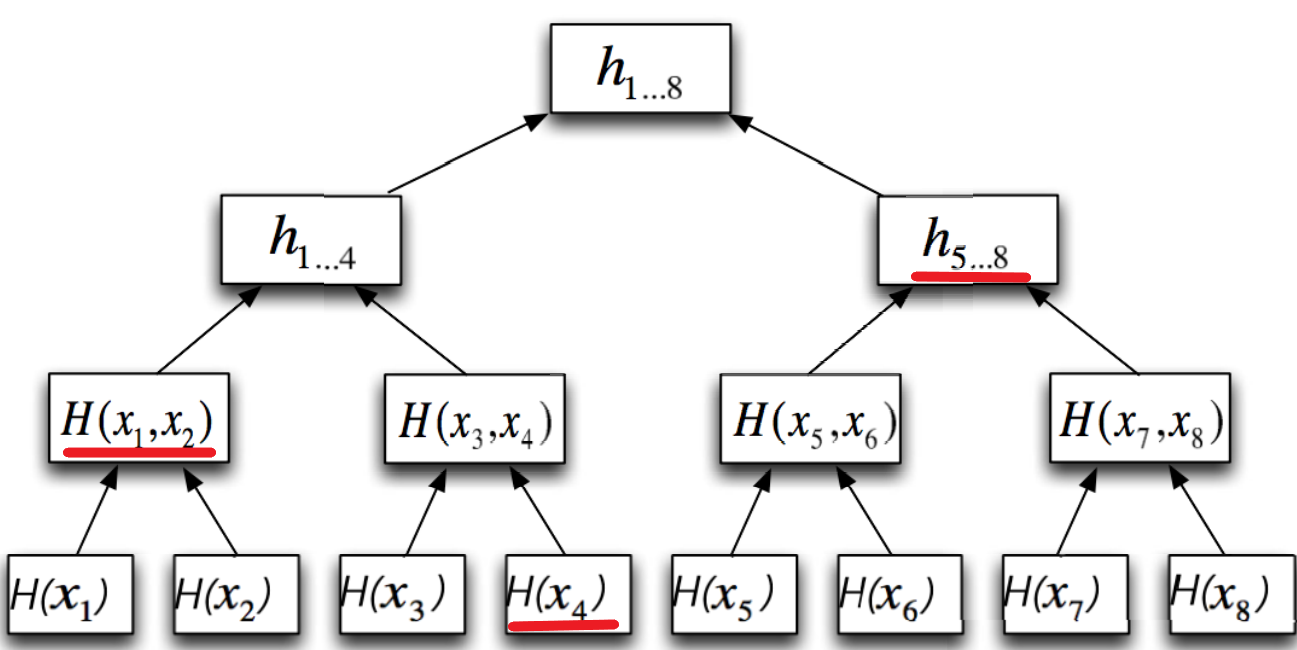
Figura 4. Merkle Tree completo
Quindi, per controllare l'integrità del file tre appena ricevuto dal Cloud, Bob controlla se il digest del file tre è stato usato per calcolare il digest presente nella radice del Merkle Tree (l'unico dato che Bob aveva conservato sul suo PC). Inizialmente, Bob calcola il digest del file tre scaricato dal Cloud, lo cancatena con il digest del file quattro e calcola il digest di questa concatenazione, ottenendo così H(x3,x4). Poi calcola il digest della stringa ottenuta concatenando H(x1,x2) con H(x3,x4), ottenendo H(x1,x2,x3,x4) (rappresentato in figura con "h1...4"). Poi concatena H(x1,x2,x3,x4) con H(x5,x6,x7,x8) e ottiene il digest finale. Infine, Bob controlla se il digest che aveva conservato sul suo PC è uguale al digest ottenuto da questa serie di calcoli: se lo è, allora nessuno ha manomesso il file numero tre; altrimenti, il file numero tre è stato modificato.
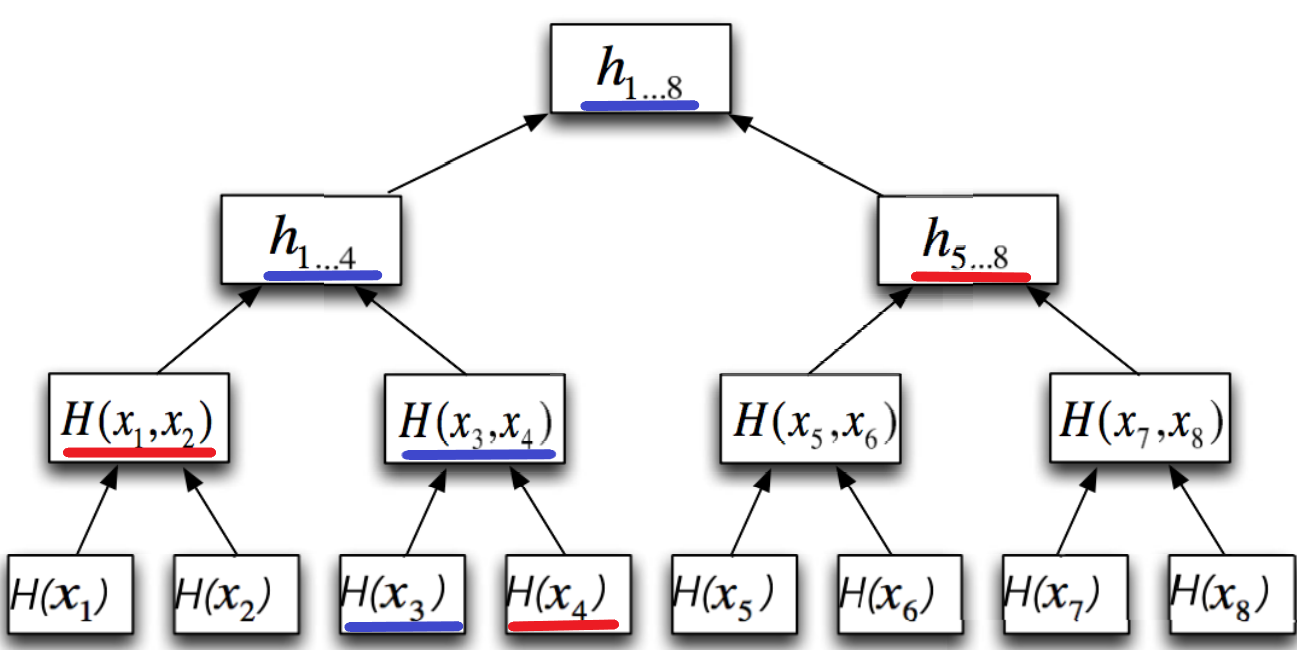
Figura 5. In rosso i digest ricevuti dal Cloud, in blu i digest che Bob calcola per verificare l'integrità.